Aanpak
2024/03/15
Jeroen Hermans

Ik denk dat ik inmiddels ruim heb laten zien wat de uitkomst van mijn onderzoek is. Maar wat ook interessant om te laten zien is hoe ik tot deze resultaten gekomen ben.
Zoals jullie hebben kunnen zien in deze serie van publicaties heb ik zo veel mogelijk bewijs bijgevoegd. B.v. in de vorm
van publiekelijk bereikbare websites, PDF bestanden en screenshots.
Het maakt het onderbouwen van mijn verhaal veel sterker en daarom ga ik vandaag laten zien welke tools ik gebruikt heb
om tot dit resultaat te komen.
Tijdens onderzoek
Wireshark en MITMproxy
Tijdens het onderzoek werd door Yealink en Lydis flink tegengas gegeven
Zo wordt het onderzoek van een mede-bron van de universiteit van Amsterdam weggezet als
stemmingmakerij
mirror
tegen China.
Het document vermeldt:
Er is dan dus geen verdere verbinding met de RPS-server of andere server van Yealink.
Het hele punt van de onderzoeker van de universiteit is juist dat er wel verbinding met een server van Yealink gemaakt wordt. En bovendien dat dit ook gebeurt voor Teams devices.
Ik heb deze resulaten zelf ook kunnen reproduceren. De manier waarop ik dit heb gedaan is om initieel met
Wireshark
te kijken op een mirror-poort van mijn router. Ik zag op die manier alle pakketten van en naar mijn device voorbij komen.
Het was toen al duidelijk dat er DNS queries werden gedaan voor o.a. rpscloud.yealink.com. Ik zag vervolgens ook verbindingen
naar het ip-adres wat de DNS server opgaf voor die hostname.
Maar om nog beter te kunnen zien wat een https-client doet heb ik
MITMProxy
geïnstalleerd. Deze proxy server gaat tussen de daadwerkelijke webserver en het Yealink device zitten. Om dit mogelijk
te maken heb ik eerst het door MITMproxy gegenereerde root certificaat geïnstalleerd als vertrouwd op
het Yealink device. MITMproxy gaat vervolgens al het TLS verkeer ontsleutelen, weergeven en opnieuw versleutelen met
het eigen root certificate.
Het is een eenvoudige test die iedereen op het werk kan doen.
NMAP
Voor het artikel over de open poort moest ik snel de gehele reeks van 65000 poorten af scannen. En wel twee keer: één keer voor TCP poorten en één keer voor UDP poorten. Ik heb dit gedaan met het commando:
nmap -sS -Pn -T5 -p- [target-ip]
En ik weet niet of jullie wel eens de
man-pages
van NMAP hebben gelezen, maar ik krijg er altijd wat hoofdpijn van.
Ik heb daarom een lijstje gemaakt van de switches die ik gebruikt heb voor de TCP scan:
-sS: TCP SYN scan
-Pn: host niet eerst pingen om te bepalen of host up is
-T<0-5>: Set timing template (higher is faster). Essentieel als je niet heel lang wil wachten.
-p-: Kort voor -p1-65535 (ofwel: alle poorten)
HAR-files
Maar soms was het ook van belang van zaken op het internet vast te leggen. Ik heb naar verschillende (fantastische)
oplossingen gekeken zoals
Hunchly
.
Maar ik was na de demo periode van deze software toch niet helemaal tevreden. Wellicht dat dit vooral kwam omdat mijn
open source hart er niet sneller van ging kloppen of omdat er niet heel veel automatisering in zat.
Ik ben daarom
Http ARchive of ‘HAR’ bestanden
gaan vastleggen. Voor de mensen met Edge, Chrome of Firefox: dit zijn bestanden waar niet
alleen de content van een web pagina is opgeslagen, maar ook alle andere data, zoals timing, cookies en headers.
Het aanmaken van een .har bestand in FireFox is mogelijk door de “Web Developer Tools” te openen.
Ga vervolgens naar het tabblad “Netwerk” en vraag nu de webpagina op die je wil vastleggen. Als je nu op het “tandwiel”-
icoon klikt kun je kiezen om van de huidige pagina een .har bestand te maken:
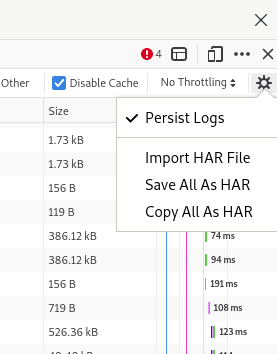
Je hebt nu een mooi bestand waar alle belangrijke data in zit. Het is ook interessant om zaken in de gaten te houden in
de headers b.v.
Online HAR reader
Hoewel een .har bestand een in principe met de hand leesbaar JSON bestand is, zou ik hier zelf een tool voor gebruiken.
Aangezien de .har bestanden die ik gemaakt heb van publieke data zijn heb ik hier regelmatig de
HAR analyzer
van Google voor gebruikt.
Voor niet-publieke pagina’s zou ik hier uiteraard voorzichtig mee zijn aangezien we weten hoe Google met privacy
omspringt.
Cyberchef
De volgende tool is is een tool van de Engelse geheime dienst! De GCHQ is wellicht het meest bekend als de partij die
dacht dat het “dremelen” van harddrives de Edward Snowden files
kon doen verdwijnen
.
Maar soms doen ze ook mooie dingen, zoals
CyberChef
. Het is een ZEER uitgebreide tool die je ook zelf kunt
hosten. Een kleine greep uit de mogelijkheden:
- van/naar base64
- url en-/decode
- unicode de-/encode
- en-/decryptie waaronder AES, 3DES, bcrypt
- JWT sign/verify/decode
- timestamp conversies
- etc…etc…etc…
Het is een hele indrukwekkende set aan tools en als je deze nog niet kent als developer of onderzoeker, dan zou ik er zeker eens een uurtje doorheen gaan lopen!
OBS Studio
Tijdens het onderzoek heb ik vele interviews afgenomen. Soms ben ik langsgegaan op lokatie, soms ging het per telefoon
en soms ging het met een videomeeting. Helaas heeft iedereen een eigen voorkeur voor een videomeetingplatform. Ik heb
meetings gehad met Microsoft Teams, Google meet en Jitsi. En niet elk platform heeft dezelfde mogelijkheden om opnames
te maken. Maar denk ook aan webinars welke mogelijk belangrijke informatie kunnen bevatten.
Ik ben daarom
OBS Studio
gaan gebruiken voor het maken van opnames van dit soort meetings. Het is een mooi open source project waarmee dit
eenvoudig is. Het is mogelijk om een opname van een scherm te maken, maar ook van een gedeelte van het scherm. Dit is
zeker bij grote schermen heel handig. Een feature welke ik zelf veel heb gebruikt is het maken van een opname van een
window. Hierdoor zal de opname nooit worden verstoord doordat ik b.v. even iets opzoek in mijn mailbox. De opname blijft
gewoon doorgaan alleen in het geselecteerde window.
OSINT
Zoals jullie hebben kunnen zien maak ik tijdens het onderzoek veel gebruik van openbare databronnen. Dit heeft als groot voordeel dat mijn bevindingen eenvoudig geverifiëerd kunnen worden. Het gebruik maken van openbare databronnen wordt ook wel Open Source Inteligence (OSINT) genoemd.
Een van de meest voor de hand liggende OSINT bron was de Kamer van Koophandel (KvK). In het handelsregister is heel erg veel informatie te vinden. Denk hierbij niet alleen aan uittreksels, maar ook aan jaarstukken, deponeringen zoals concernverklaringen en oprichtingsactes. Ik heb uitvoerig gebruik gemaakt van de KvK in het artikel bedrijfseconomisch.
Een ander mooie openbare bron is het Kadaster. In dit register kun je opzoeken wie de eigenaar is van een adres. Ik heb dit bijvoorbeeld geraadpleegd voor het artikel over Yealink Europe.
Uiteraard blijft google natuurlijk een hele handige bron van data. Maar de Google zoekmachine heeft ook heel handige zoekopties zoals “filetype:pdf” waarmee er alleen PDF bestanden gezocht kunnen worden.
Voor het zoeken naar websites die offline zijn of voor het bekijken van eerdere versies van een website is de Wayback machine een geweldige tool.
Voor het artikel over Yealink Europe wilde ik graag weten wie de eigenaar was van IBS B.V. Hiervoor heb ik zogenaamde WhoIS data van dit domein gebruikt. Hoewel niet meer alle informatie te vinden is in publieke data blijft dit een krachtige tool.
Toen ik voor het artikel over Yealink Europe meer wilde weten over de relevante wetgeving heb ik hier een mooie website voor gebruikt van de Rijksoverheid. Absoluut een aanrader die ik al tijdens eerdere onderzoeken heb gebruikt.
In het artikel over de AVG had ik te maken met een certificaat van TÜV Rheinland. Deze organisatie heeft een website certipedia waar het mogelijk is om te zoeken in alle actieve certificaten. Helaas heb ik geen functie kunnen vinden om ook in de vervallen certificaten te zoeken.
Encryption/decryption tool
Soms is de beste manier om de werking ergens van te achterhalen om het na te bouwen. Dat is exact wat ik heb gedaan met
de
Yealink Encryption Tool
. Door deze tool letterlijk
na te bouwen en open source vrij te geven was het mogelijk om ook extra functionaliteit toe te voegen. Voordat Yealink
hun default key verwijderde kon deze tool ook provisioning documenten ontsleutelen.
Gelukkig zag Yealink na mijn demo met deze tool in dat het niet meer houdbaar was om een hardcoded RSA sleutel te blijven
gebruiken.
De reden dat deze tool pas zo laat gereleased is komt omdat er nog een fix uitgerold moest worden door Yealink. Maar
mijn open source tool is nog steeds heel bruikbaar om provisioning documenten te versleutelen met een eigen sleutel.
Ook is deze tool handig om te controleren of je eigen provisioning documenten nog versleuteld zijn met de oude,
gelekte, RSA sleutel.
Forensisch bewijs
Op het moment dat je aan een publicatie gaat werken dan weet je ook dat er op enig moment je bevindingen in twijfel
getrokken worden. Het was dus van groot belang om “vluchtige” openbare data veilig te stellen op een manier waarmee
achteraf aannemelijk gemaakt kan worden dat ik deze niet tussentijds zelf heb gewijzigd.
Daarom heb ik de open source tool Ella gemaakt:

Ella is behalve
deze tool
ook een kat. En zoals elk katten baasje weet: er is niets in het huis wat aan de aandacht
van een kat ontsnapt. En dat is precies waar deze tool voor gebouwd is.
Het is een command-line tool waardoor het mogelijk is om deze bijvoorbeeld dagelijks automatisch te draaien.
Ella maakt gebruik van een headless browser en gaat hiermee een lijst van url’s af. Op deze pagina’s detecteert de
tool alle PDF bestanden. Vervolgens worden alle url’s met het
SPN2 protocol
in de Wayback Machine geplaatst. Dus mochten jullie je tijdens de afgelopen weken hebben afgevraagd hoe het kan dat ik
altijd netjes Wayback Machine mirror links kan plaatsen bij de artikelen, dan weten jullie nu hoe dit kan!
Maar wat Ella ook doet is het committen van de .har bestanden en PDF bestanden naar een github repository. Op deze manier
is het eenvoudig te zien wanneer een bestand wijzigt door een commit en is het ook niet aannemelijk dat ik ongezien
data kan wijzigen. Dat is voor bewijslast achteraf heel erg handig.
Hunchly is een mooie tool, maar ik denk dat Ella een tweetal grote voordelen heeft:
- Het draait “in de cloud”. Daar waar Hunchly data lokaal wordt opgeslagen, doet Ella dit in de Wayback Machine en github waardoor het b.v. eenvoudig is te gebruiken in een artikel.
- Het kan op een machine met weinig resources geagendeerd (cron) draaien zonder dat ik hier zelf aan hoef te denken.
Website
Vrijwel direct nadat duidelijk was dat Follow The Money ging publiceren over Yealink en Lydis viel het op dat mijn website bijzondere aandacht uit het buitenland kreeg. Ik heb daarom besloten om te gaan onderzoeken hoe ik een website kan maken die zowel goed te onderhouden is en ook geen PHP of python nodig heeft. Dit heeft niet alleen maar voordelen voor de snelheid van de site, maar een statische website heeft ook een veel kleinere aanvalsvector.
Na wat omzwervingen kwam ik terecht bij
Hugo
. Hugo is een open source tool
geschreven in python. Pagina’s worden gemaakt in markdown language, waarna Hugo deze “compileert” naar statische
.html pagina’s.
Hugo kan worden uitgebreid met custom extensies die ook eenvoudig zelf te maken zijn. Een voorbeeld zijn de quotes
welke ik door de publicaties veelvuldig gebruik. Ook de rode censuur regels zijn een custom “shortcode” welke ik heb
gemaakt voor Hugo.
Het levert een website op die enorm snel is en geen database of PHP nodig heeft. Maar ik ben nog een stapje verder
gegaan. De website welke jullie nu aan het lezen zijn draait op de servers van GitHub. Dat werkt als volgt:
Op het moment dat ik een nieuwe versie van de website maak (b.v. de release van een artikel), dan maak ik een commit
naar de main branch van de website github repository. Dit triggert een github action. Deze github action download de laatste
versie van Hugo, compileert de static site en commit deze naar de “public” branch. De public branch van deze repository
is als “github pages” ingesteld. Door de cloudaware.eu DNS records naar de github servers te laten verwijzen kan dit ook
op het eigen domein plaatsvinden.
Het gevolg is een website die overal ter wereld snel te bereiken is, en ook lastig te beïnvloeden is met DDOS aanvallen.
Het is uiteraard niet nodig om github pages te gebruiken, maar door het gebruik van Hugo (en dus puur statische website)
is het gebruiken van services als CloudFlare bijzonder effectief.
Tot slot is scheiding van content (.md) en layout (.html, .css) iets waar ik het conceptueel erg mee eens ben.
Het volgende artikel is een conclusie en samenvatting van de afgelopen weken aan publicaties. Het betekent ook voorlopig een einde aan de artikelen over Lydis en Yealink. Het betekent niet dat het onderzoek ten einde is, maar er komen voorlopig geen regelmatige publicaties meer, tenzij er bijvoorbeeld iets nieuws te melden is.
Voor de laatste keer tot volgende keer!